【开源Git】爬虫项目,支持小红书、抖音、快手、B站、微博
如果是涉及到运营的小伙伴能用得上,本项目在github上已有 14.8K star了。我当初学python的时候就是为了爬虫🤣,不过爬虫都是从入门到入狱,没把握好尺度很容易违法的哦!
仓库介绍
涉及到的编程语言:python,非业余人员可以pass了,你可能看不懂!诚实博主不骗你🥱
要求版本:3.7-3.9,我的是3.10运行时就有各种问题
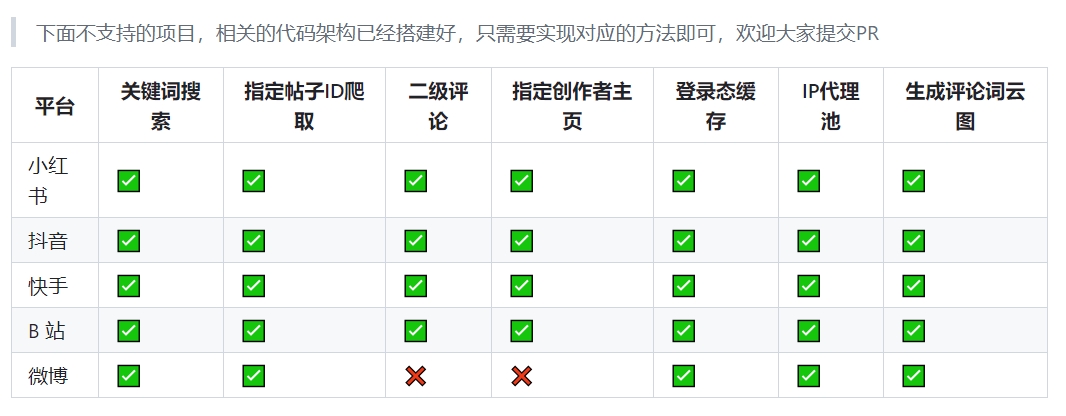
目前能抓取小红书、抖音、快手、B站、微博的视频、图片、评论、点赞、转发等信息。
原理:利用playwright搭桥,保留登录成功后的上下文浏览器环境,通过执行JS表达式获取一些加密参数 通过使用此方式,免去了复现核心加密JS代码,逆向难度大大降低
git仓库:https://github.com/NanmiCoder/MediaCrawler
功能列表
使用
克隆仓库
注:需要安装git和python
1 | git clone https://github.com/NanmiCoder/MediaCrawler.git |
创建并激活 python 虚拟环境
1 | # 进入项目根目录 |
虚拟环境如果激活失败:
输入:set-executionpolicy remotesigned,回车输入Y
安装依赖库
pip install -r requirements.txt
安装playwright
playwright install
运行爬虫
1 | ### 项目默认是没有开启评论爬取模式,如需评论请在config/base_config.py中的 ENABLE_GET_COMMENTS 变量修改 |
数据保存
- 支持保存到关系型数据库(Mysql、PgSQL等)
- 执行 python db.py 初始化数据库数据库表结构(只在首次执行)
- 支持保存到csv中(data/目录下)
- 支持保存到json中(data/目录下)
有问题可以去git提交issue
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 梧桐的学习日记!




公告
欢 迎 访 问 a c w y 的 学 习 日 记

微信:acwy0718
邮箱:awy0718@gmail.com